CPU 취약점 시리즈 - 멜트다운

CPU 취약점 시리즈 - 멜트다운
파이프라인 구조
CPU의 성능을 높이기 위해서는 여러가지 측면의 접근 방법들이 있고, 제조사들은 이런 방법들을 다방면으로 적용하여 CPU의 성능 및 효율성을 높이고 있습니다. 이 중 단일 코어 성능을 높이기 위해서 CPU는 파이프라인(Pipeline)을 사용합니다.
파이프라인은 CPU의 명령어 실행을 크기 인출(Fetch), 해석(Decode), 실행(Execute), 메모리(Memory), 저장(Write Back) 단계로 나눕니다. 만약 파이프라인이 없을때 명령어를 3개 실행한다고 가정해봅시다. 명령어는 직렬로 실행되어야 하기 대문에 아래와 같이 총 15사이클이 소요됩니다.
1
2
3
4
Clock Cycle 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Instruction1 F D E M W
Instruction2 F D E M W
Instruction3 F D E M W
그러나 파이프라인을 통해서 각각의 유닛들이 병렬로 동작이 가능하다면 아래와 같이 7사이클만에 실행이 가능합니다.
1
2
3
4
Clock Cycle 1 2 3 4 5 6 7
Instruction1 F D E M W
Instruction2 F D E M W
Instruction3 F D E M W
CPU의 클럭은 가장 긴 스테이지의 시간만큼을 요구하기 때문에 파이프라인을 통해서 단계를 세분화 시킴으로서 클럭을 향상시키는 것이 쉬워지게 됩니다. 그렇다고 마냥 파이프라인을 깊게 하면 분기 예측 적중률 저하등의 문제가 있기 때문에 그 정도를 잘 조절해야 합니다. 실제 상용 CPU에서는 10 ~ 15깊이의 파이프라인을 사용하며 아키텍쳐마다 차이가 있습니다.
당연히 단점이 있습니다. 의존성이나 충돌등으로 유휴상태(stall)가 발생한다는 점입니다. 그리고 이런 상황은 생각보다 자주 발생하며, 적절한 처리 없이는 연산결과가 엉망이 되어버릴 수 있습니다. 예를들어서 아래 명령어를 보겠습니다. 데이터 의존성이 발생하였습니다. 두번째 명령은 rax 레지스터에 의존성을 가지고 있습니다. 우리가 기존에 예제로 들었던 인출, 해석, 실행 세 단계의 파이프라인으로 생각하면 1사이클의 유휴상태가 발생합니다.
1
2
add rax, rbx
add rcx, rax
이런 데이터 의존성 문제 이외에도 분기 명령어, 하드웨어 리소스 부족(메모리 포트 등)등이 유휴상태를 발생시킬 수 있고 이런 문제를 해저드(Hazard)라고 합니다. 해저드가 발생 시 별도의 처리 없이는 연산이 매우 느리게 실행될 것입니다. 때문에 CPU의 파이프라인에서는 유휴시간을 줄이고 연산의 결과는 정확하게 계산될 수 있도록 비순차적실행(Out of order execution), 분기 예측(Branch Prediction) 등을 사용합니다. 멜트다운과 스펙터 취약점은 이런 성능을 위한 기법들이 보안검사를 무시하고 실행될 수 있다는 점을 악용합니다.
비순차적 실행
현대의 많은 CPU는 명령어 수준 병렬처리(ILP)을 달성하기 위하여 Tomasulo’s algorithm 을 개선시켜서 사용하고 있습니다. 여기에는 비순차적 실행이 포함되며 성능을 최대한 끌어내기 위해서 여러개의 실행기를 가지고 있는 슈퍼스칼라(Superscalar) 구조를 채택하였습니다. 슈퍼스칼라 프로세스는 실행기가 여러개이기 때문에 비순차적 실행으로 의존성이 없는 명령어들을 동시에 처리할 수 있습니다. 실행기가 2개인 2-way 슈퍼스칼라 프로세서에서는 아래처럼 2개의 명령어를 동시에 처리가 가능합니다.
1
2
3
Clock Cycle 1 2 3
Instruction1 F D E
Instruction2 F D E
비순차적 실행(OoO 라고 줄여 부르기도 함)은 명령어가 순차적으로 처리되는 것이 아니라 파이프라인의 스톨을 최소한으로 유지하기 위해서 명령어의 실행 순서를 바꾸어 실행하는 방식입니다. 예를 들어보겠습니다. 순차적 실행으로 아래와 같은 연산을 처리한다고 가정하겠습니다. 이번에는 Memory 와 WriteBack 단계를 추가하겠습니다. Memory는 메모리 작업, WriteBack 은 레지스터에 상태를 반영하는 단계입니다. 두번째 명령어는 첫번째 명령어의 R1 에 의존성을 가지고 있지만 세번째 명령어는 의존성을 가지고 있지 않습니다. 그러나 마지막 명령어는 지연되어 실행됩니다. 두번째 명령어의 이전 단계가 끝나지 않았기 때문입니다.
1
2
3
4
Clock Cycle 1 2 3 4 5 6 7 8 9 10
ADD R1,R2,R3 F D E M W
ADD R4,R1,R6 F D - - E M W
ADD R7,R8,R9 F D - - - E M W
비순차적 프로세서에서는 ADD R7,R8,R9와 ADD R4,R1,R6 의 순서를 바꿈으로서 전체 실행 시간을 줄일 수 있습니다.
1
2
3
4
Clock Cycle 1 2 3 4 5 6 7 8
ADD R1,R2,R3 F D E M W
ADD R7,R8,R9 F D E M W
ADD R4,R1,R6 F D - E M W
우리의 프로세서는 슈퍼스칼라 프로세서이니까 두개의 실행기로 실행할 수 있습니다.
1
2
3
4
Clock Cycle 1 2 3 4 5 6 7 8
ADD R1,R2,R3 F D E M W
ADD R7,R8,R9 F D E M W
ADD R4,R1,R6 F D - E M W
실제로 CPU는 어셈블리어를 계산하는 것이 아니라 명령어 디코드하여 마이크로 명령어(μOPs) 로 분해를 합니다. 아래 명령어로 예를 들어보겠습니다.
add [rbx + 8], rax
mov rcx, rax
1
2
3
4
5
LEA p3, [p2+ 8] ; p2 == rbx
MOV p4, [p3]
ADD p4, p1 ; p1 == rax
MOV [p3], p4
MOV p5, p1 ; p5 == rcx
와 같은 마이크로 명령어로 분해될 수 있습니다. 여기서 p1 ~ p4 는 물리 레지스터로 CPU 내부에서 연산을 처리하기 위해서 사용하는 레지스터입니다. CPU는 수백개 이상의 물리레지스터를 이용하여 의존성 문재를 해결하기 위해서 노력합니다. 이렇게 분해된 명령어는 리오더 버퍼(ROB)로 들어갑니다. 리오더 버퍼는 비순차적 프로세서에서 순서대로 명령어의 결과를 커밋(commit)하기 위한 버퍼입니다. 명령어가 커밋되기 전까지는 임시 결과값이 아키텍처 상태에 반영되지 않으며, 롤백이 가능한 상태로 유지됩니다 이후 명령어 스케줄링 과정을 거치며 각 명령어의 의존성 분석이 이루어집니다. 이를 예약 스테이션(Reservation Station) 과정이라고 합니다. 예약 스테이션에선는 각 오퍼랜드의 의존성을 분석하여 태깅을 하고, 실행이 끝난 명령어에 대해서는 태깅된 오퍼랜드에게 브로드캐스팅을 통해서 의존성이 없는 명령들이 실행될 수 있도록 항목을 업데이트 해줍니다. 위 예제에서 LEA p3, [p2+ 8] 와 MOV p5, p1 는 명백하게 의존성이 존재하지 않습니다. 슈퍼스칼라 프로세서이기 때문에 두 연산은 동시에 실행될 수 있습니다.
1
2
3
4
5
LEA p3, [p2 + 8] ; 실행 완료 - 커밋됨
MOV p4, [p3] ; 실행중 - 헤드(Head)
ADD p4, p1 ; 대기
MOV [p3], p4 ; 대기
MOV p5, p1 ; 실행 완료 - 커밋 대기
두가지 명령이 동시에 실행된다고 하더라도 결과는 연산의 순서를 반영하기 위해서 동시에 처리되지 않습니다. 헤드가 커밋되지 않으면 이후의 명령어들은 커밋되지 않고 우리에게 결과가 보이지 않습니다. 메모리 관련 작업들은 Store buffer 와 Load buffer에서 대기를 하게 됩니다. 만약 예외(Exception)가 발생하게 된다면 커밋을 대기하고 있는 명령어들은 롤백되게 됩니다.
비순차적 실행과 비슷하게 투기적 실행은 다음 명령이 실행될 것 같으면 미리 실행하는 방식입니다. 예를들어서 분기가 될 것 같다면 분기지점의 명령을 미리 실행함으로서 파이프라인을 미리 채울 수 있습니다. 물론 예측이 틀린다면 파이프라인을 다시 비워야(flush) 하기 때문에 리스크가 크지만, 분기 예측 버퍼(Branch Target Buffer)를 이용한 분기 예측기는 보통 90% 이상의 정확도로 이를 예측할 수 있습니다. 이렇게 코드를 미리 실행하는 것을 투기적 실행(Speculative execution)이라고 합니다.
위의 ROB를 생각한다면 투기적 실행으로 미리 실행된 명령어들은 커밋을 대기하다가 실제 조건 분기가 참인 경우에는 커밋이되고, 조건 분기가 거짓이면 롤백이 될 것 입니다.
CVE-2017-5754(Meltdown Variant 3)
멜트다운은 이런 투기적 실행의 특징에 기반하여 유저가 접근권한이 없는 메모리에서 값을 유추할 수 있는 취약점입니다. 리눅스에서 디버거로 메모리 맵을 봤을 때 커널메모리 주소는 보이지 않습니다. 그러나 사실 우리에게 메모리 맵을 노출하지 않는 것일 뿐, 실제로는 매핑이 되어있습니다.

이는 커널 디버거로 확인하면 볼 수 있습니다. 0xffff 로 시작하는 주소가 커널 메모리 입니다. 즉 커널 메모리에 접근했을 때 오류가 나는 이유는 권한이 없어서 발생하는 것이지, 가상 메모리 주소 자체가 물리주소와 매핑되어있지 않은 것이 아닙니다.
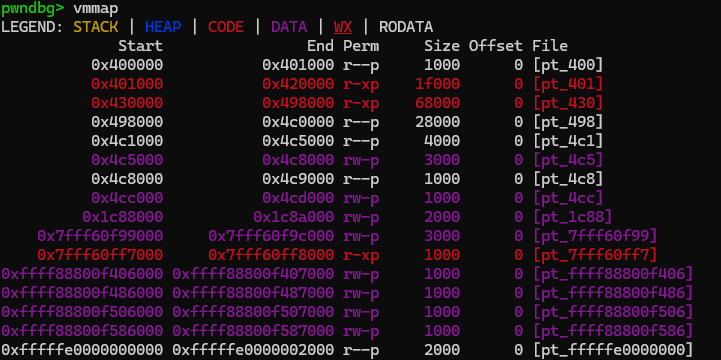
적절한 권한이 없다면 페이지 폴트(Page Fault; PF)가 발생하고 CPU는 커널 레벨에서 동작하는 페이지 폴트 핸들러를 호출합니다. 핸들러는 SIGSEGV 시그널을 커널 메모리에 접근한 유저 프로세스에게 보내주고 유저가 등록한(또는 기본으로 설정되어있는) 핸들러가 이 시그널을 받아서 처리하게 되는 것입니다. 유저 권한으로 커널 메모리에서 값을 가지고 오는 상황을 가정하겠습니다.
1
2
3
; rbx = 유저 배열
mov rax, [KERNEL ADDRESS]
mov rcx, [rbx + rax]
메모리가 커널 메모리인지 유저 메모리인지 확인하려면 어떻게 해야할까요? 주소상으로 가장 큰 차이점은 커널 메모리가 0xffff 로 시작한다는 것입니다. 그러나 0xffff 로 커널 주소가 시작하는 이유는 관습과 하드웨어 요구사항일 뿐 커널/유저를 구분짓는 결정적인 요인이 될 수 없습니다. Canonical Addressing 에 따르면 주소의 48 ~ 63 번째 비트(정확히는 최대로 쓸 수 있는 주소 비트. 몇몇 서버용 CPU를 제외한 대부분의 CPU는 6바이트 이상의 주소를 사용할 수 없다.)는 모두 1 또는 0이여야 하며 아닐경우 오류가 발생합니다. 따라서 메모리가 커널(Supervisor) 메모리인지 유저메모리인지 확인하기 위해서는 페이징 메모리 관리 기법을 알아야 합니다.
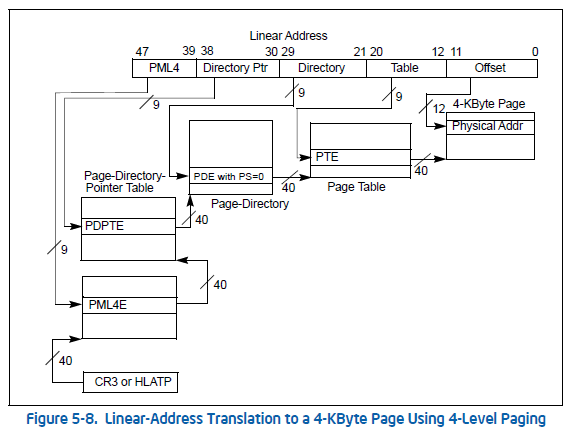
주소의 특정 비트를 인덱스로 사용해서 최종 PTE 를 참조하여 물리주소를 찾아나가는 방식입니다. 그리고 PTE 에서 R/W 비트를 통해서 읽기/쓰기권한의 여부와 U/S 비트를 통해서 유저 메모리인지 권한을 확인할 수 있습니다.

따라서 특정 주소가 유저의 메모리인지 확인하고 싶다면 최소한 1번의 메모리 참조가 필요합니다. 만약 PML4E 의 U/S 비트가 1이라면 하위 엔트리들은 모두 유저 엔트리일 것이니까요. 최악의 경우에는 4번의 참조가 필요할 것입니다. 하지만 주소하나에 접근하기위해서 메모리를 다단계로 접근하는 것은 굉장히 비용이 많이들기 때문에 보통은 TLB(Translation Lookaside Buffer)에서 처리가 됩니다. TLB는 가상주소를 물리주소로 변환해주는 MMU(Memory Management Unit)의 속도를 높여주는 캐시입니다. TLB에는 주소 뿐만아니라 메모리 권한도 모두 캐싱이 되기 때문에 빠른속도로 메모리에 접근할 수 있습니다.
다시 코드로 돌아오겠습니다. 이제 직접 커널 주소에 접근에서 값을 가지고와야 하지만 메모리는 너무나도 느립니다. 따라서 캐시메모리에 접근합니다. 캐시메모리는 물리주소가 있어야만 캐시 히트/미스를 결정할 수 있습니다. 만약 해당 커널 주소가 캐싱되어있다면 메모리 참조 없이 매우 빠른 속도로 값을 가지고 올 수 있습니다.
1
2
3
; rbx = 유저 배열
mov rax, [KERNEL ADDRESS]
mov rcx, [rbx + rax]
캐시 메모리는 L1 → L2 → L3로 가는 계층 구조인데, L2, L3 캐시와 다르게 L1 캐시는 CPU 코어에 가장 가깝게 위치하고 가장 빠른 속도를 요구하기 때문에 보통 VIPT(Virtual Indexed, Physically Tagged) 구조를 사용합니다. 해당 캐시의 특징은 캐싱된 데이터를 찾기 위해서 가상주소와 물리주소를 동시에 사용한다는 점입니다. 가상주소를 통한 캐시 인덱싱과 TLB(Translation Lookaside Buffer)를 통한 물리주소 변환이 거의 병렬적으로 동작하게 됩니다. TLB는 가상주소를 물리주소로 변환하는 과정을 가속화하는 캐시로, 페이지 테이블 엔트리를 저장하여 페이지의 물리주소와 함께 읽기/쓰기/실행 권한 정보도 함께 포함하고 있습니다.
이제 문제가 발생합니다. 메모리 접근 과정 중 권한 부족으로 TLB에서 예외가 발생했습니다. 그러나 슈퍼스칼라와 같은 복잡한 구조로 인하여 즉시 파이프라인을 플러시시키는 것은 원치 않을 뿐더러 성능 손실이 큽니다. 인텔 CPU는 이 시점에서 중요한 설계 결정을 내렸습니다. TLB에서 물리주소를 얻는 것과 권한을 확인하는 과정을 분리하여 병렬로 처리합니다.
1
2
3
4
5
6
7
시간축 →
[TLB 조회 시작] ─────┐
├─→ [물리주소 획득] → [데이터 로드 시작] → [캐시에 저장]
│
└─→ [권한 검사] ────────────────────→ [예외 발생!]
↓
[롤백 시도]
커밋 단계에서 취소를 하면서 ROB(Reorder Buffer)에서 자동으로 뒤에 있는 명령들을 롤백하기로 결정합니다. 대부분의 메모리 접근은 성공하기 때문에 권한 문제가 발생할지 모르고 투기적 실행으로 커널에서 가져온 rax 값을 인덱스로 하여 유저 배열에 접근합니다. 이 과정에서 유저 배열이 캐싱되었습니다. 투기적 실행 도중, 이전에 예외가 발생했던 명령어의 예외 처리기가 실행되면서 투기적으로 실행된 명령들은 모두 롤백됩니다. 그러나 캐시에 유저 배열이 들어가면서 배열을 하나씩 접근해보면 캐싱된 인덱스는 접근이 빠를 것입니다. 이를 통해서 커널에서 가져온 값을 알 수가 있습니다. (물론 별도의 예외처리기가 없다면 프로그램이 종료될 것이므로 별도의 예외처리기를 등록해야 합니다)
투기적 명령이 실행되는 시점에 권한 문제가 있다는 것을 이미 알고 있습니다. 아키텍처별로 정확한 취약점의 발생 방법은 다를 수 있더라도 기본적으로 지연된 예외처리로 취소되어야 할 명령의 결과가 캐시에 반영되어 생긴 문제입니다.
효과적인 멜트다운 공격을 위해서는 타겟 주소가 TLB에 캐싱되어 있어야 합니다. TLB 미스가 발생하면 페이지 테이블 워크에 수백 사이클이 소요되어 투기적 실행 윈도우를 초과할 가능성이 높기 때문입니다. 따라서 공격자는 시스템 콜 등을 통해 커널이 특정 주소에 접근하도록 유도하여 TLB를 “프라이밍”한 후 공격을 수행합니다.
1
2
[TLB 미스] → [페이지 테이블 워크 시작] → ... → [물리주소 획득]
└─ 이 시간이 너무 길어서 투기적 실행이 취소될 가능성 높음
다른 CPU 제조사들도 지연된 예외처리를 사용하지만 멜트다운 취약점은 주로 인텔 CPU와 일부 ARM Cortex-A 시리즈에서 발생했습니다. 인텔은 권한 검사에 실패함에도 L1 캐시의 데이터를 사용합니다. 다른 제조사들은 캐시에서 0으로 마스킹된 값을 반환하여 데이터를 사용할 수 없게 만들거나, 투기적 실행 명령이 결과를 반환하지 않도록(지연 등을 통해서 명령이 취소된 것으로 보입니다) 하였습니다.
공격방법
1
2
3
; rbx = 유저 배열
mov rax, [KERNEL ADDRESS]
mov rcx, [rbx + rax]
공격자는 프로브 배열을 생성할 때 256개 페이지 크기(256 * 4096 = 1MB)로 만듭니다. 각 바이트 값(0x00~0xFF)이 서로 다른 페이지에 매핑되도록 4096바이트(페이지 크기) 간격으로 배치합니다. 이렇게 하는 이유는 캐시라인이 64바이트이므로, 같은 페이지 내의 여러 위치가 한 캐시라인에 들어가 정확한 측정을 방해하기 때문입니다.
1
2
uint8_t probe_array[256 * 4096];
첫 번째 명령어가 실행되면 커널 메모리에서 1바이트를 읽어 rax에 저장합니다. 예를 들어 커널 메모리의 값이 0x42라면, 두 번째 명령어는 probe_array[0x42 * 4096] 위치를 읽게 됩니다. 이때 중요한 것은 실제로 배열의 모든 위치에 의미 있는 데이터가 있을 필요는 없다는 점입니다. 단지 해당 위치가 캐시에 로드되었다는 사실만 중요합니다. 이때 첫 번째 명령어가 실행되면 유저 모드에서 커널 메모리에 접근하므로 SIGSEGV(Segmentation Fault)가 발생합니다. 기본적으로 SIGSEGV 시그널은 프로그램을 종료시키지만, 프로그램이 종료되면 공격을 계속할 수 없으므로, 공격자는 시그널 핸들러를 미리 등록하여, 공격을 이어갈 수 있도록 해야합니다.
투기적 실행이 롤백된 후, 공격자는 256개의 페이지를 순차적으로 접근하면서 시간을 측정합니다:
1
2
3
4
5
6
7
8
9
for (i = 0; i < 256; i++) {
start = rdtsc();
temp = probe_array[i * 4096];
elapsed = rdtsc() - start;
if (elapsed < CACHE_HIT_THRESHOLD) {
// i가 커널에서 읽은 값!
}
}
캐시 히트는 보통 50 사이클 이하, 캐시 미스는 200 사이클 이상이므로 구분이 가능합니다. **노이즈를 줄이기 위해 같은 공격을 여러 번 반복하고 통계적으로 처리합니다. 위 과정으로 커널메모리에서 1바이트를 읽었기 때문에 이를 반복하면 더 많은 양의 데이터를 유출할 수 있습니다. 실제 공격을 구현한 라이브러리는 https://github.com/isec-tugraz/meltdown 에서 확인해보세요. libkdump.c 소스코드를 확인해보시면 됩니다.
참고자료
- Computer Architecture: A Quantitative Approach by John L. Hennessy and David A. Patterson
- Meltdown: Reading Kernel Memory from User Space
- Spectre Attacks: Exploiting Speculative Execution
- Intel 64 and IA-32 Architectures Optimization Reference Manual
- Meltdown and Spectre : redhat 2018
- https://en.wikipedia.org/wiki/Memory_ordering
- https://en.wikipedia.org/wiki/Tomasulo’s_algorithm
- https://stackoverflow.com/questions/49601910/out-of-order-execution-vs-speculative-execution
- https://blog.stuffedcow.net/2018/05/meltdown-microarchitecture/