Dynamic Binary Instrumentation with Intel Pin
동적 이진 계측(DBI)와 Intel Pin에 대한 내부 동작 원리와 최적화 기법들을 다룹니다.

목차
- Dynamic Binary Instrumentation with Intel Pin
- Probe vs JIT
- Pin 기초
- 응용 : 윈도우 GUI 앱 리버싱
- DBI 아키텍쳐
- 여러가지 DBI
- 참고자료
Dynamic Binary Instrumentation with Intel Pin
안녕하세요! knights of the space의 멤버로 활동하고 있는 김영민(OSORI)입니다. 이번 글은 DBI(동적 이진 계측)와 유명한(?) DBI 중 하나인 Pin에 대한 내용입니다.
우리는 디버거를 통해서 특정 코드에 중단점을 걸고, 메모리를 조작하는등의 행동을 할 수 있습니다. 그리고 이는 보통 중단점의 주소에 있는 명령어를 0xCC(int 3) 으로 바꿔서 인터럽트를 처리하는 식으로 동작합니다. 디버거는 처음 프로그램을 분석할 때 매우 유용한 도구입니다. 그러나 몇몇 디버거로는 확인하기 힘든 작업들이 종종 존재합니다. 예를들어서 어떤 프로그램이 fopen 함수로 파일을 여는 것을 확인했을 때, 모든 파일의 목록을 확인하고 싶다면 어떨까요? 한두개 정도야 중단점으로 확인하면서 기록하면 되겠지만, 수십개 수백개의 파일 목록들을 확인하는 것은 굉장히 귀찮은 작업이 될 것 입니다.
동적 바이너리 계측(dynmaic binary instrumentation; DBI)는 이런상황에서 효과적인 분석 방법입니다. 기존에 디버거로 걸던 중단점이 해당 지점을 0xCC로 바꾸었다면, DBI 프레임워크는 내가 만든 코드로 진입하는 지점을 만들어줍니다. 그리고 후킹 코드 실행 후 다시 원래 지점으로 복귀합니다. 이를 이용하면 해당 프로그램의 컨텍스트에서 돌아가는 코드를 만들 수 있기 때문에 함수의 인자, 메모리 상황등을 프로그래밍적 방법으로 보거나 제어하는 것이 가능합니다.
DBI 를 잘 이용하면 메모리 누수, 보안 테스팅, 코드 커버리지 분석 등 다양한 활동을 할 수 있습니다. 런타임시에 가진 모든 정보를 활용할 수 있기 때문이죠. 본 포스팅 DBI 프레임워크 특히 PIN을 예제로 하여 내부 동작을 알아보도록 하겠습니다.
Probe vs JIT
DBI 는 보통 Probe 방식과 JIT(Just-In-Time) 방식으로 나뉩니다. Probe 방식은 후킹이라는 표현으로 대체하면 이해가 쉬울 것 같습니다. 유명한 DBI 프레임워크 중 하나인 frida 가 해당 방식을 기본적으로 제공하고 있습니다. Probe 방식은 보통 함수의 시작점의 명령어를 후킹 코드(Trampoline)로 jmp 하는 인스트럭션으로 덮어쓰는 방식입니다. frida 로 한번 테스트 해볼까요? 아래와 같은 샘플 프로그램을 컴파일 하고 MessageBoxA 함수를 후킹해보겠습니다.
1
2
3
4
5
6
7
8
9
10
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <Windows.h>
int main()
{
MessageBoxA(NULL, "test", "test", 0);
getchar();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
const user32 = Module.findBaseAddress('user32.dll');
const messageBoxA = Module.findExportByName('user32.dll', 'MessageBoxA');
Interceptor.attach(messageBoxA, {
onEnter: function(args) {
const text = args[1].readCString();
const caption = args[2].readCString();
console.log('[+] MessageBoxA called:');
console.log(' Text:', text);
console.log(' Caption:', caption);
console.log(' Type:', args[3]);
}
})
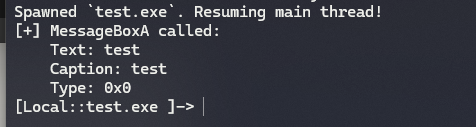
getchar 함수는 디버거를 붙이기 전에 프로그램 종료 방지를 위해서 넣어줬습니다. 간단한 frida 스크립트로 MessageBoxA 함수의 인자들을 출력하였습니다. frida 가 타겟이 되는 프로그램을 실행한 이후 getchar 에서 대기할 때 디버거를 붙여보겠습니다. 일단 눈에 띄는 것은 frida_agent 라는 모듈이 로드되어있습니다.
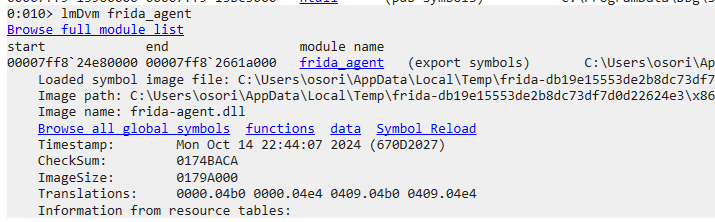
MessageBoxA 함수를 디스어셈블리 해보겠습니다. 먼저 frida 를 붙이기 이전 원본 코드입니다.
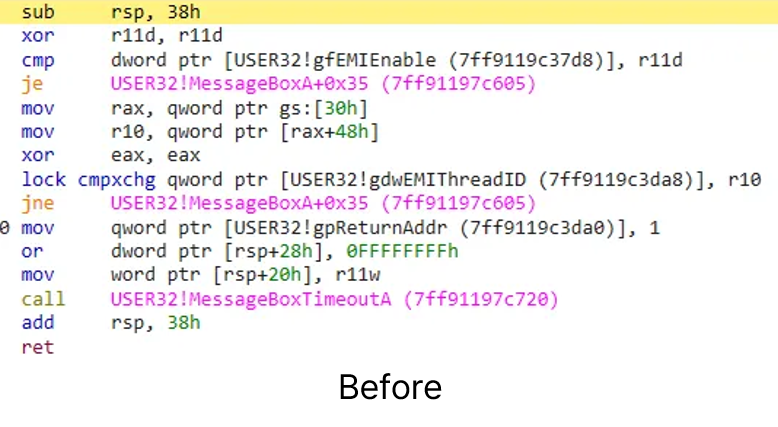
다음은 frida 가 붙었을 때의 코드입니다.
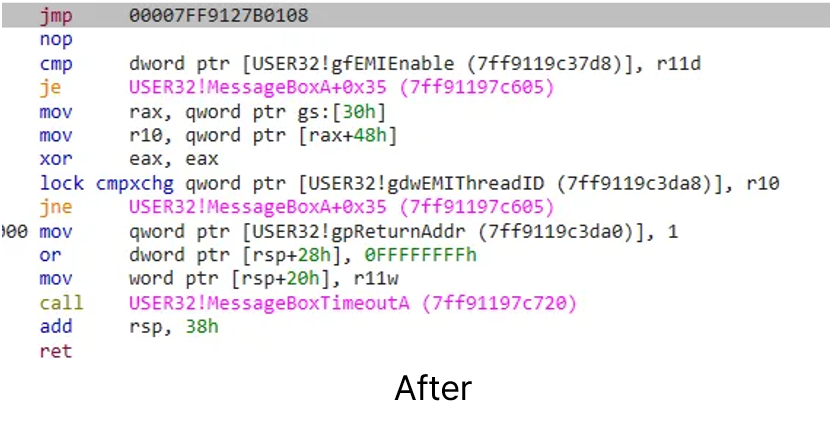
차이가 보이시나요? sub rsp, 38h , xor r11d, r11d 두개의 인스트럭션이 jmp 명령어로 대체되고 남는 부분은 nop 이 들어갔습니다. jmp 의 타겟이 되는 지점은 제가 작성한 자바스크립트 코드를 실행하는 부분입니다. frida 에서는 Interceptor 라고 부르는 Probe 방식은 구현이 쉽고 오버헤드가 적다는 장점이 있지만, 복잡한 분석이나 상세한 계측이 어렵다는 단점이 있습니다. 그러나 오버헤드가 적다는 장점이 매우 강력하기 때문에 간단한 후킹에 많이 사용되는 방법입니다.
다음으로는 JIt(Just-In-Time) 방식입니다. JIT은 원본 코드를 실행 시점에 동적으로 번역하여 실행하는 방식입니다. 따라서 별도의 JIT 컴파일러가 필요하고, 코드가 최초로 JIT 컴파일 될 때 오버헤드가 크기 때문에 속도가 느립니다. 그러나 Probe 와 다르게 원본 코드의 수정을 하지 않고 계측이 가능하며, 모든 명령어 수준에서 계측이 가능하기 때문에 굉장히 강력하다고 볼 수 있습니다. JIT 방식의 DBI 들은 별도의 VM을 요구합니다.
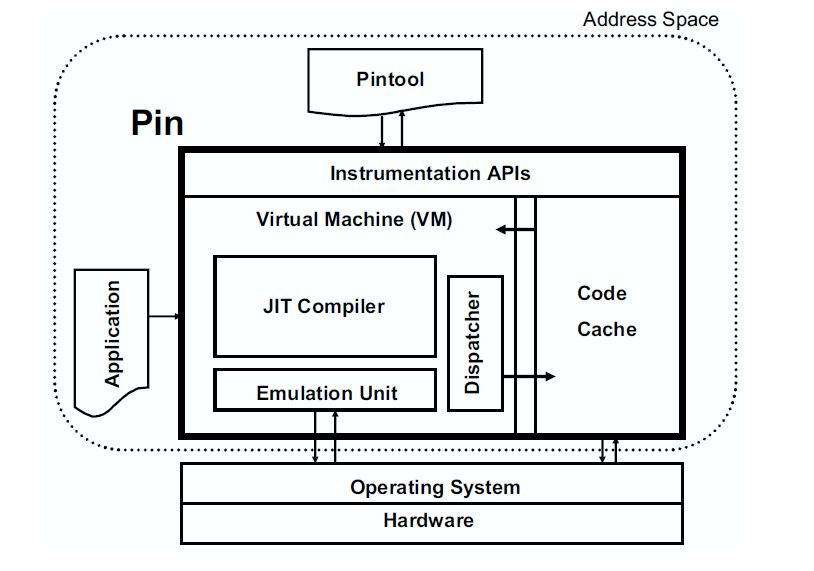
위 그림은 Pin 의 소프트웨어 아키텍쳐입니다. 세세한 구현은 다르겠지만 DynamoRIO, QDBI 와 같은 JIT 기반 DBI 들도 비슷한 구조를 띄고 있습니다. Pin 에서 Pintool 은 유저가 작성하는 후킹 코드(frida 예제에서 자바스크립트에 해당합니다), Application 은 분석의 대상이 되는 프로그램입니다. 이 두가지 정보를 VM 에서 애플리케이션을 실행하면서 JIT 컴파일을 통해서 계측 코드가 포함된 코드로 컴파일 및 실행하고 코드캐시에 저장하여 재사용 할 수 있게 합니다. 좀 더 쉽게 예를 들어보면 위에서 MessageBoxA 함수의 첫 2개의 인스트럭션이 바뀐 것이 JIT 컴파일된 결과물이고 이 코드가 코드캐시에 저장되어 MessageBoxA 함수 실행시에 VM에서 실행된다고 볼 수 있겠습니다.
이 처럼 모든 코드의 실행이 VM에서 관리되기 때어 모든 인스트럭션에 대한 정보를 토대로 작업을 수행할 수 있기 때문에 디버거나 정적분석으로는 쉽게 얻기 힘든 정보들을 손쉽게 추출할 수도 있습니다. 예를들자면 대부분에 cpu 에 존재하는 AES-NI 명령어 세트는 AES 암호화/복호화를 CPU의 전용 회로로 수행하는 명령어입니다. 만약 특정 프로그램에서 AES 명령어로 파일을 암호화 복호화 한다고 가정할때, 키를 모른다면 AESKEYGENASSIST 같은 명령어에 계측을 해서 키 값을 바로 알아낼 수 도 있습니다. 이렇게 리버싱에도 사용할 수도 있고 취약점 테스팅, 메모리 누수 점검, 최적화(캐시 시뮬레이션) 등 개발에도 사용할 수 있는 만큼 굉장히 유용한 기술이라고 할 수 있겠습니다.
Pin 기초
Pin은 콜백(Callback)형식으로 설계되었습니다. 아래는 Pin 튜토리얼에 있는 Pintool 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// This function is called before every instruction is executed
VOID docount() { icount++; }
// Pin calls this function every time a new instruction is encountered
VOID Instruction(INS ins, VOID* v)
{
// Insert a call to docount before every instruction, no arguments are passed
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)docount, IARG_END);
}
int main(int argc, char* argv[])
{
// Initialize pin
if (PIN_Init(argc, argv)) return Usage();
OutFile.open(KnobOutputFile.Value().c_str());
// Register Instruction to be called to instrument instructions
INS_AddInstrumentFunction(Instruction, 0);
// Register Fini to be called when the application exits
PIN_AddFiniFunction(Fini, 0);
// Start the program, never returns
PIN_StartProgram();
return 0;
}
main 함수에서 INS_AddInstrumentFunction 함수를 호출합니다. 해당 함수는 INS(Instruction) 객체에 대해서 콜백을 걸 수 있는 기회를 제공하는 함수입니다. 콜백을 거는 함수가 아님에 주의하세요! Instruction 함수는 최초 실행되는 지점의 명령어에 대해서만 적중합니다. 따라서 Instruction 함수에서 INS 객체를 통해서 해당 지점의 명령어를 분석하는 것이 아니라, INS_InsertCall 함수를 호출해서 해당 INS 에 대해서 콜백을 걸어야 합니다. 위 예제는 프로그램이 실행되면서 실행되는 모든 인스트럭션의 수를 카운팅하는 코드인데, 만약 INS_InsertCall 을 사용하지 않고 docount 함수를 바로 호출 했다면 반복문 처럼 같은 코드가 여러번 실행되는 지점에서 카운팅이 되지 않아 틀린 결과가 나올 것 입니다. INS 외에도 베이직블록, 인스트럭션 시퀸스인 TRACE 등 다양한 객체를 다룰 수 있으니 자세한 내용은 Pin API 문서를 참고하세요. 추가로 INS 객체의 경우 Pin에서도 매우 다양한 API를 지원하지만, Intel XED(X86 Encoder Decoder) 에서 사용가능한 xed 객체로 변환하여 더 로우 레벨 API를 호출할 수 도 있습니다!
응용 : 윈도우 GUI 앱 리버싱
특정 프로그램에 대한 어느정도의 사전 정보가 존재할 때 DBI의 가치는 올라갑니다. 예를들어서 윈도우 앱을 리버싱할 때, 버튼 커맨드를 처리하는 함수를 찾고 싶을 수 있습니다. 기본적으로 윈도우의 GUI 앱들은 WNDPROC 콜백을 이용해서 메세지를 처리하는데 이 때 uMsg 인자가 WM_COMMAND(0x111) 인 경우 버튼 클릭 이벤트입니다.
1
2
3
4
5
6
7
LRESULT Wndproc(
HWND hWnd,
UINT uMsg,
WPARAM wParam,
LPARAM lParam
)
Pin 을 이용해서 함수의 두번째 인자가 0x111 인 경우를 찾아보겠습니다. Pin 은 비교적 높은 수준의 API를 제공하기 때문에 우리가 직접 스택이나 레지스터에서 함수 호출의 인자를 가지고 올 필요가 없습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#include "pin.H"
#include <fstream>
#include <map>
#include <string>
std::ofstream TraceFile;
std::map<ADDRINT, std::pair<std::string, ADDRINT>> ModuleMap;
// 모듈 로드시 호출되는 콜백
VOID ImageLoad(IMG img, VOID *v) {
ModuleMap[IMG_LowAddress(img)] = std::make_pair(
IMG_Name(img),
IMG_HighAddress(img) - IMG_LowAddress(img)
);
TraceFile << "Module Loaded: " << IMG_Name(img)
<< std::hex
<< " Base: 0x" << IMG_LowAddress(img)
<< " Size: 0x" << IMG_HighAddress(img) - IMG_LowAddress(img)
<< std::endl;
}
std::string FindModule(ADDRINT addr) {
for(const auto& module : ModuleMap) {
if(addr >= module.first &&
addr <= (module.first + module.second.second)) {
return module.second.first + "+0x" +
std::to_string(addr - module.first);
}
}
return "Unknown";
}
//call 에 대해서 호출되는 콜백
VOID CheckCallArg(ADDRINT ip, ADDRINT arg2) {
if(arg2 == 0x111) {
TraceFile << std::hex
<< "\nCall at IP: 0x" << ip
<< " (" << FindModule(ip) << ")"
<< "\nSecond argument: 0x" << arg2
<< std::endl;
}
}
VOID Instruction(INS ins, VOID *v) {
if(INS_IsCall(ins)) {
INS_InsertCall(
ins,
IPOINT_BEFORE,
(AFUNPTR)CheckCallArg,
IARG_INST_PTR,
IARG_FUNCARG_CALLSITE_VALUE, 1,
IARG_END
);
}
}
VOID Fini(INT32 code, VOID *v) {
TraceFile << "\nFinal Module List:" << std::endl;
for(const auto& module : ModuleMap) {
TraceFile << module.second.first
<< std::hex
<< " Base: 0x" << module.first
<< " Size: 0x" << module.second.second
<< std::endl;
}
TraceFile.close();
}
int main(int argc, char *argv[]) {
if(PIN_Init(argc, argv)) {
return -1;
}
TraceFile.open("call_trace.txt");
TraceFile << "=== Analysis Started ===" << std::endl;
IMG_AddInstrumentFunction(ImageLoad, 0);
INS_AddInstrumentFunction(Instruction, 0);
PIN_AddFiniFunction(Fini, 0);
PIN_StartProgram();
return 0;
}
간단하게 프로그램의 모듈 정보를 기록하고(디버깅을 위해서), 모든 call 명령어에 대해서(INS_IsCall ) 계측을 해주었습니다. Instruction 함수가 핵심코드로 IARG_FUNCARG_CALLSITE_VALUE 로 인덱스 1, 즉 2번째 함수 인자를 가지고 올 수 있고 이 인자는 CheckCallArg 의 arg2 에 매칭됩니다.
간단한 프로그램에 적용시킨 결과는 아래와 같습니다. user32.dll 에서도 뭔가 많이 히트가 되었네요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Call at IP: 0x764c745b (C:\Windows\SysWOW64\user32.dll+0x226395)
Second argument: 0x111
Call at IP: 0x764c7461 (C:\Windows\SysWOW64\user32.dll+0x226401)
Second argument: 0x111
Call at IP: 0x4668dc (C:\Program Files (x86)\****.exe+0x420060)
Second argument: 0x111
Call at IP: 0x43f435 (C:\Program Files (x86)\****.exe+0x259125)
Second argument: 0x111
Call at IP: 0x4606cc (C:\Program Files (x86)\****.exe+0x394956)
Second argument: 0x111
Call at IP: 0x764b5bd2 (C:\Windows\SysWOW64\user32.dll+0x154578)
Second argument: 0x111
Call at IP: 0x764b3a40 (C:\Windows\SysWOW64\user32.dll+0x145984)
Second argument: 0x111
Call at IP: 0x764b0af0 (C:\Windows\SysWOW64\user32.dll+0x133872)
첫번째 0x764c745b 주소를 IDA 로 디컴파일 해보겠습니다. 의도대로 _InternalCallWinProc 함수가 잡혔네요. wndproc 과 연관있는 함수가 잡힌 것을 보아 잘 작동한 것을 알 수 있습니다.
1
2
3
4
5
6
7
8
9
int __stdcall _InternalCallWinProc(int (*a1)(void), int a2, int a3, int a4, int a5)
{
int result; // eax
__writefsbyte(0xFCAu, __readfsbyte(0xFCAu) | 1);
result = a1();
__writefsbyte(0xFCAu, __readfsbyte(0xFCAu) & 0xFE);
return result;
}
u ***으로 마스킹 한 프로그램의 주소로 가면 실제 버튼 클릭시 호출되는 함수의 루틴의 시작점을 찾을 수 있을 것 입니다. 어디서 부터 시작할지 모를때도 유용하게 쓸 수도 있고, 추가적인 정보를 안다면 더 구체적인 코드 작성을 통해서 특정 부분을 찾을 때 매우 유용하게 쓸 수 있을 것 입니다. 메모리 누수를 추적하는 것도 조금만 응용하면 바로 할 수 있겠죠.
DBI 아키텍쳐
DBI를 설계하는 것은 굉장히 복잡합니다. JIT 컴파일러 구현만으로도 상당히 어려운일인데, 최적화적인 요소에서 고려해야 할 사항이 많습니다. 또한 모든 코드를 계측하는 것은 불가능합니다. 특권 명령어 같은 경우가 이에 속합니다. 몇가지 문제점을 한번 짚고 넘어가보겠습니다.
재진입 문제
가장 대표적으로 재진입(reentrant) 문제가 있습니다. 아래 코드를 한번 보겠습니다.
1
2
3
4
5
6
7
8
9
10
VOID instrument()
{
int* a = (int*)malloc(sizeof(int));
free(a);
}
VOID Instruction(INS ins, VOID* v)
{
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)instrument, IARG_END);
}
모든 명령어에 대해서 콜백으로 malloc 과 free 를 반복하고 있습니다. 코드 자체가 의미없는 짓을 반복하고 있다는 점만을 제외하면 (그리고 퍼포먼스도!!!) 작동에는 큰 문제가 없어보입니다. malloc 함수 내부 명령어에도 콜백이 들어가버리면 어떻게 될까요? malloc 내부에서 instrument 콜백이 호출되면서 malloc을 호출하고 다시 instrument 콜백의 호출이 반복됩니다. 이 문제는 모든 DBI 프레임워크가 해결해야하는 숙명입니다. Pin은 해당 문제를 자체 CRT(C-Runtime) 을 만드는 것으로 해결했습니다.
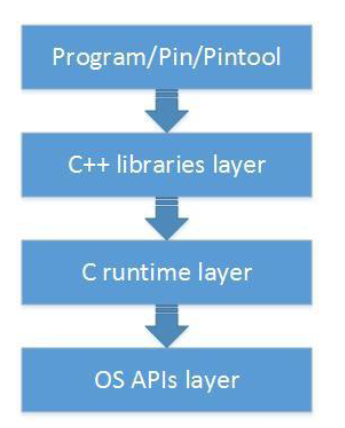
자체 C++ 라이브러리와, C 런타임 그리고 OS Specific 한 API들을 처리하는 레이어를 가지고 있어 라이브러리에서 발생하는 재진입 문제를 해결할 수 있었습니다. 단점이라고 하면 최신 C++ 문법들이 바로바로 반영되지 않는다는점이 단점입니다. 실제로 Pin 의 MSVC(Microsoft Visual C++) 버전은 C++03 표준 지원에 머물러 있습니다. 하지만 괜찮습니다. 윈도우에서도 LLVM 이 지원됨에 따라 Clang 버전을 사용하면 C++11 문법을 사용할 수 있기 때문이죠. 이 외에도 다른 해결방법이 존재합니다. 아키텍쳐 자체 설계를 통해서 유저가 작성하는 계측 코드가 DBI 레이어를 통해서 프로그램과 통신시키는 방법, 마지막으로 계측하지 않는 코드 설정등이 있겠습니다.
최적화
최적화는 DBI의 핵심입니다. 많은 코드를 JIT 컴파일 해놓을 수록, DBI 의 성능이 높아지게 됩니다. 이유는 컨텍스트 스위칭입니다. 실행중 JIT 컴파일 되지 않은 코드를 만나게 될 경우, 애플리케이션의 컨텍스트에서 DBI 프레임워크의(VM) 컨텍스트로 전환되어 다시 JIT 컴파일 후 코드가 실행되게 됩니다. 이 과정에서 많은 오버헤드가 발생하게 됩니다. 따라서 최대한 많은 코드를 JIT 컴파일하는 것이 중요합니다. 여기서 Trace 라는 개념이 등장하게 됩니다.

Intel Pin 공식 문서에는 Trace를 하나의 입구, 여러개의 출구를 가진 인스트럭션의 시퀀스로 정의하고 있습니다. 즉 분기로 끝나는 코드의 실행흐름이라고 쉽게 이해할 수 있습니다. CALL, RET 등의 (무조건)분기 명령어를 만나면 하나의 Trace는 종료되게 됩니다. 처음 봤을때는 좀 생소한 개념이고 이해가 쉽지 않습니다. 따라서 직접 Pintool 을 제작해서 테스트를 해보았고 아래 그림에서 각각의 색깔의 박스로 구성된 Basic Block 들이 Trace를 구성하고 있는 것을 알 수 있었습니다.
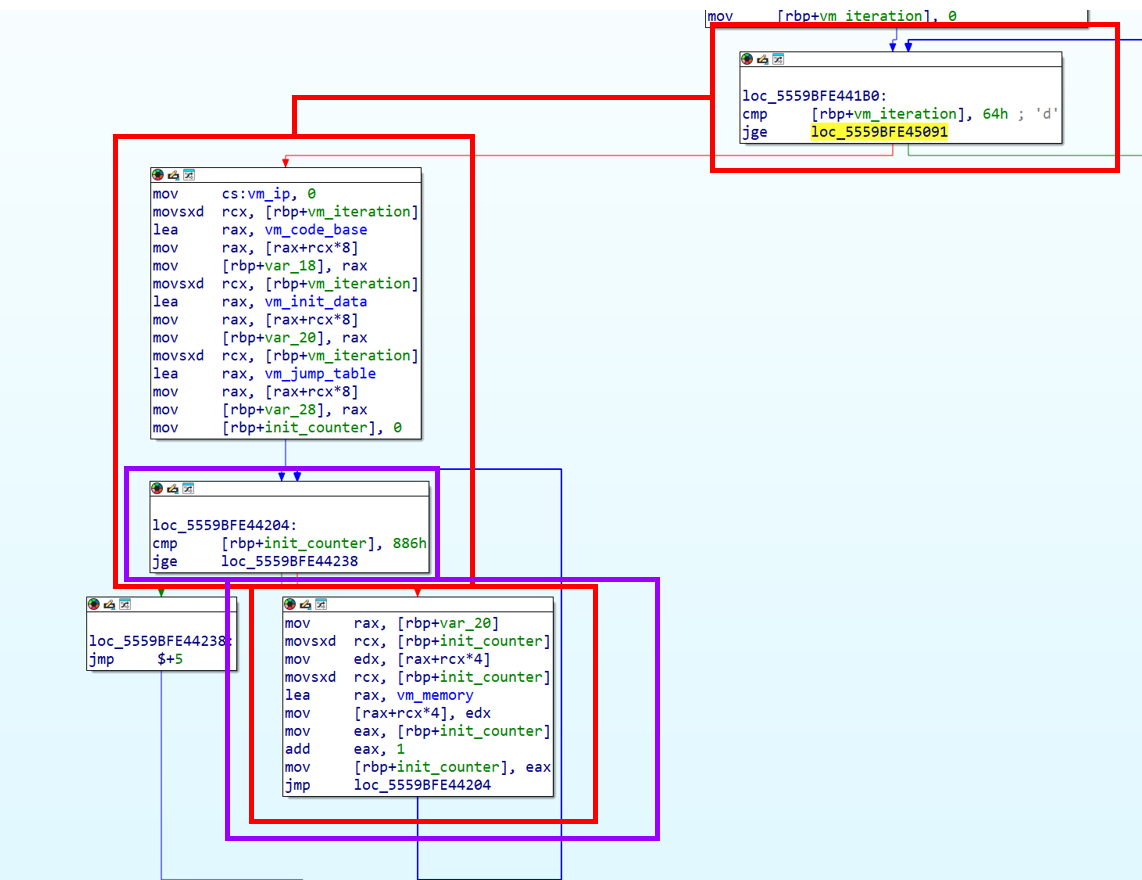
재미있게도 첫번째 보라색 박스는 빨간색 박스와 겹치는 부분이 있습니다. 반복문 때문에 발생한 일인데, Trace 의 중간으로 jmp가 발생하는 경우, 그 지점부터 다시 Trace 가 생성되게 되며, 각각의 Trace 는 무조건 분기 명령어로 끝나는 것을 볼 수 있습니다. 또한 Trace가 너무 커지는 경우도 코드 캐시의 관점에서 보았을 때 좋지 않기 때문에 Trace 내부에서는 일정 개수의 분기 명령어를 포함하면 다음 Trace로 넘어가게 설계되어있습니다. 제가 테스트 했을 때는 내부에 3개 이상의 Basic Block 은 포함되지 않았습니다… 만 다른 경우가 있을 수 도 있겠죠.
Trace Linking 은 이러한 여러개의 Trace 묶음으로서 컨텍스트 스위칭을 줄이는 기법입니다.
- Trace Linking이 없는 경우: trace A -> VM -> trace B -> VM -> trace C -> …
- Trace Linking이 있는 경우: trace A -> trace B -> trace C -> … (필요한 경우에만 VM으로 점프)
이 방법을 이용하면 VM으로 돌아가는 경우를 최대한 줄일 수 있습니다. PIN 의 Trace linking 은 아래처럼 동작합니다.
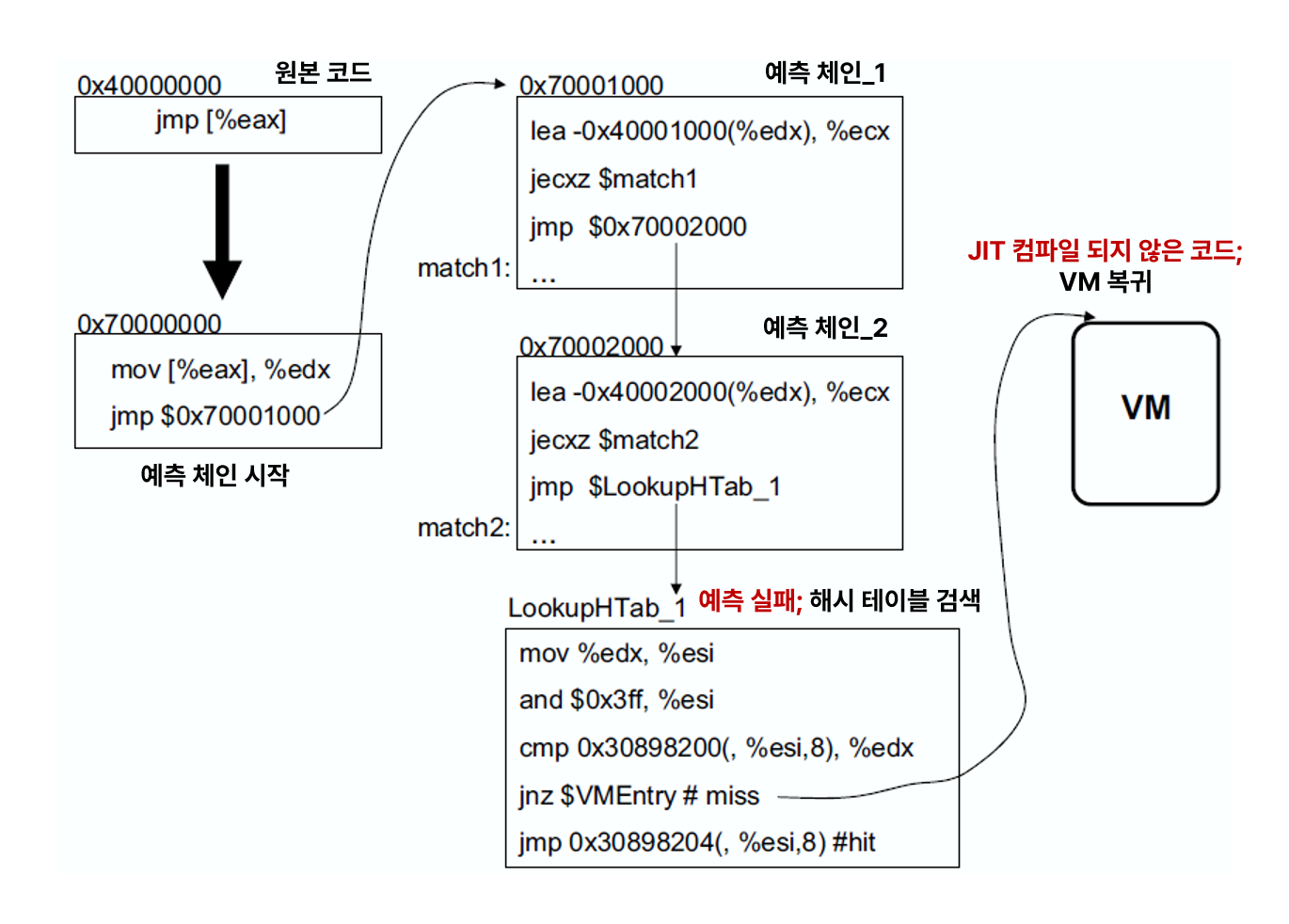
위 상황에서 Trace 의 끝은 jmp [eax] 명령어이고, 해당 Trace에서 0x40001000 또는 0x40002000 으로 jmp 했던 과거 기록을 바탕으로 위와 같은 두개의 예측체인이 생성되었습니다. 만약 예측에 실패하는 경우 마지막으로 Trace 들이 저장되어있는 해시 테이블을 검색합니다. 해시테이블에서도 존재하지 않는다면, JIT 컴파일되지 않은 코드일 것이기 때문에 VM으로의 복귀가 필연적입니다. 이 체인은 동적으로 증분될 수 있고, 새로운 요소가 체인의 앞, 뒤에 삽입될 수 있기 때문에 다양한 정보들로 성능을 높일 수 있습니다. 또한 예측 체인에서도 최적화를 위해서 jecxz 명령어가 사용되었습니다. 이 명령어는 cmp , test 와 달리 eflags 를 수정하기 않기 때문에, 별도의 eflags 복구가 필요하지 않다는 장점이 있습니다.
Trace linking 에서 직접 호출로 Trace가 끝나는 것은 큰 문제가 되지 않습니다. 분기의 주소를 알고 있기 때문에 쉽게 링킹이 되지만 간접호출(ex : call rax )은 그렇지 않습니다.
우리는 Trace linknig 처리에 앞서서 CPU에서 사용하는 하드웨어적 구조를 알 필요가 있습니다(꼭 필요한가..?). RSB와 BTB입니다. RSB(Return Stack Buffer)는 RET 명령어의 빠른 처리를 도와주는 LIFO 버퍼입니다. 이 버퍼는 최대 16개의 항목을 저장할 수 있다고 하네요. CPU는 RSB 를 통해서 Return Address 를 예측함으로서 파이프라인의 지연을 최소화 할 수 있습니다.
BTB(Branch Target Buffer)는 분기예측에 쓰이는 일종의 캐시입니다. 파이프라이닝의 Fetch 단계에서 이 BTB를 참조하여 분기의 목적지 주소를 가지고 올 수 있고, 다음 명령어를 가지고 올 수 있습니다.
문제점은 RET 명령어 처리에서 발생합니다. RET 명령어는 하드웨어적으로 RSB 를 이용해서 성능을 높일 수 있지만, Trace linknig 을 하게 되면 RET 또한 분기명령어로 취급되기 때문에 RSB 의 이점을 전혀 살릴 수 없게 됩니다. 따라서 내부적으로 BTB 를 이용하게 될 것이고, 논문에 따르면 이 경우의 오버헤드는 약 5~20% 정도라고 합니다. 이를 해결하기 위해서 PIN은 함수 복제(function cloning) 기법을 도입하였습니다.
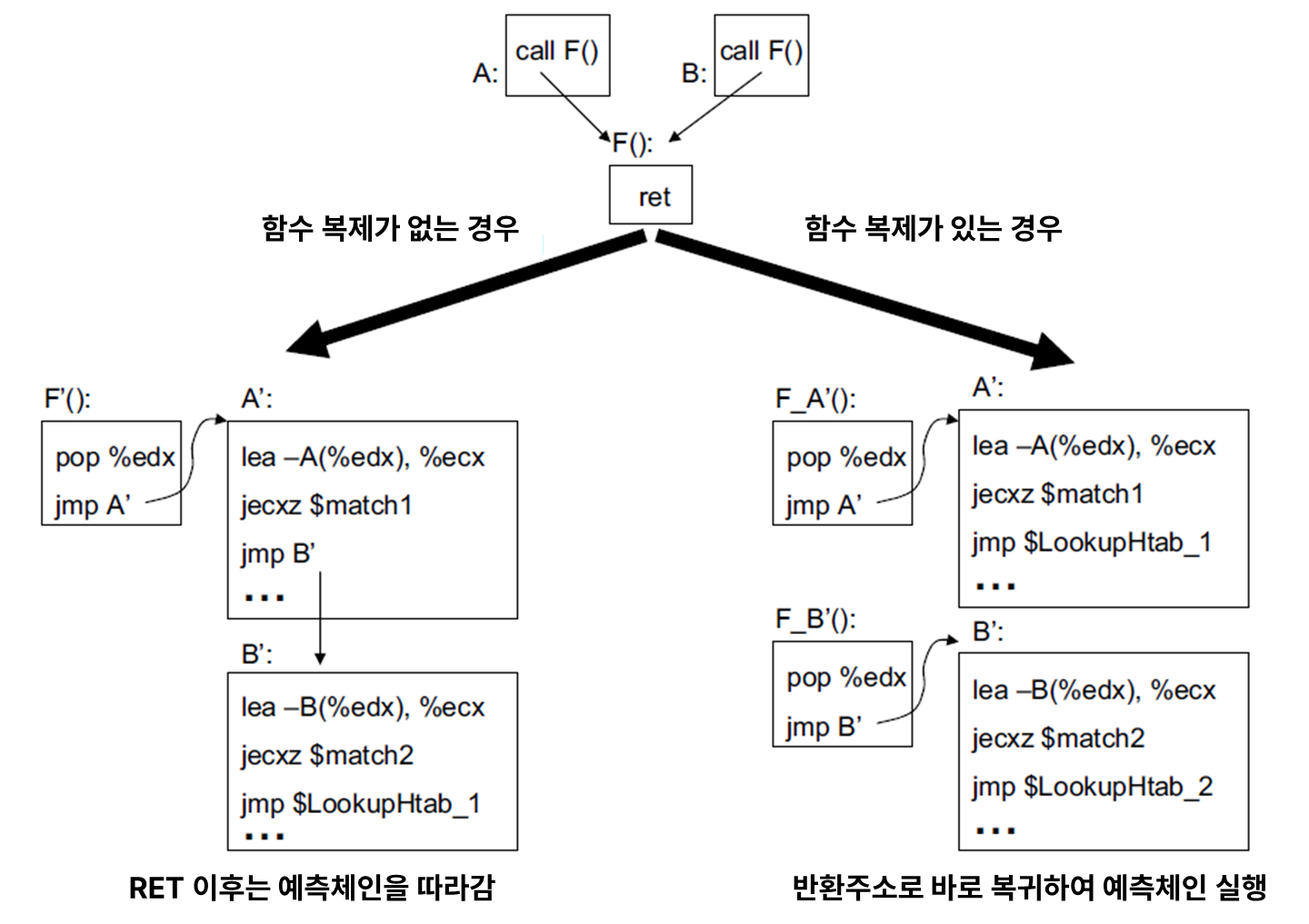
위 그림에서는 다른 사이트에서 실행된 함수를 복제하여 ret 명령어 이후 바로 해당 지점으로 점프하고 각각의 예측체인을 실행하는 것을 볼 수 있습니다.
마지막으로 레지스터 재할당 기법입니다. JIT 컴파일을 하며 추가되는 코드에서는 추가적인 레지스터가 필요할 수 있습니다. 단순히 위에서 소개한 예측 체인에서도 ecx, edx 레지스터를 추가적으로 사용하고 있습니다. 만약 기존 컨텍스트에서 해당 레지스터들을 사용하고 있다면 문제가 발생하게 되고 이를 해결하기 위한 추가 코드 삽입(push, pop 과 같은)은 필연적으로 오버헤드를 유발하게 됩니다.
PIN은 이 문제를 해결하기 위해서 레지스터의 Liveness 분석(더이상 사용되지 않는 레지스터 찾기)을 통한 바인딩을 통해서 문제를 해결합니다. 예제를 들어보겠습니다. 다음과 같은 원본 코드가 있다고 가정하겠습니다.
1
2
3
4
5
6
7
8
9
label trace_1:
mov eax, 1
mov ebx, 2
cmp edx, ecx
jz trace2
...
label trace2:
add eax, 1
sub ebx, 2
이 문제를 해결하는 가장 편한 방식은 모든 레지스터 값을 메모리에 저장하여 관리하는 것입니다. 유명한 DBI 메모리 디버깅 도구인 Valgrind가 이러한 방식을 사용합니다. 아래 코드가 그 예입니다. ebx → esi 로 재할당되었으며 Trace 내부에서 사용한 레지스터인 eax, esi 를 메모리에 저장합니다. 간단하지만 매번 추가적인 코드가 삽입되어야 하기 때문에 비효율적인 방식입니다. 여기서 EAX, EBX 는 레지스터가 아닌 스필링 영역으로, Pin 이 가상레지스터의 값을 일시적으로 저장하기 위해 사용되는 스레드 로컬 메모리입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
label trace_1:
mov eax, 1
mov esi, 2
cmp edx, ecx
mov EAX, eax
mov EBX, esi
jz trace2
...
label trace2:
mov eax, EAX
mov edi, EBX
add eax, 1
sub ebx, 2
PIN은 별도의 바인딩 테이블을 사용합니다. 아래 표대로 가상레지스터와 실제 레지스터간 바인딩(binding)이 이루어집니다.
| Virtual | Physical |
|---|---|
| eax | eax |
| ebx | esi |
| ecx | ecx |
| edx | edx |
아래 상황에서 trace 1 은 미리 컴파일 되있다고 가정할 때 trace2(는 별도의 레지스터 바인딩 조정 없이 컴파일이 가능합니다.
1
2
3
4
5
6
7
8
9
label trace_1:
mov eax, 1
mov esi, 2
cmp edx, ecx
jz trace2'
label trace2'
add eax, 1
sub esi, 2
...
그러나 만약 아래와 같이 trace 2가 미리 컴파일 되어있고 trace1 을 컴파일(JIT) 해야 되는 상황이라면 어떨까요?
1
2
3
4
label trace2'
add eax, 1
sub edi, 2
...
원본 코드와 비교했을 때 ebx → edi 로 바인딩되있기 때문에 위의 바인딩 테이블을 사용할 수 없습니다. 해당 테이블에서는 ebx → esi 로 바인딩 되어있기 때문이죠. 물론 trace2 를 재컴파일해도 되지만, 이는 비용 낭비일 확률이 높습니다. 위 경우에서 trace1의 출구부분에 아래와 같이 메모리에 저장되는 메모리 영역인 스필링 영역을 활용하여 레지스터를 조정해주는 코드를 삽입할 수 있습니다.
1
2
3
4
5
6
7
label trace1:
mov eax, 1
mov esi, 2
cmp edx, ecx
mov EBX, esi
mov edi, EBX
jz trace2
이러한 최적화 기술들을 사용하여 Pin은 DynamoRIO 와 Valgrind 보다 속도면에서 우위를 점할 수 있다고 합니다. 실제로는 Pin을 활용해봤을 때 오버헤드는 2x ~ 10x 정도로 보면 됩니다. JIT 컴파일이 이루어진 후에는 상당히 빠른 속도로 코드가 실행되기 때문에 재사용되는 코드가 얼마냐 많냐에 달려있을 것 같네요.
여러가지 DBI
지금까지 간단하게 Pin 과 DBI 에 대해서 소개를 드렸습니다. 마지막으로는 다른 DBI 도구들을 정리해보고 포스팅을 마치려고 합니다. 첫번째로 Frida 입니다. Windows, Linux, macOS, Android, IOS 과 같은 다양한 OS와 x86, arm 아키텍쳐를 지원합니다. 다른 DBI 와 다르게 Frida 는 Probe 모드를 주로 사용하지만 Stalker 를 이용하여 인스트럭션 단위 계측도 가능합니다. JavaScript 로 스크립팅 할 수 있기 때문에 빌드를 안해도 된다는 장점이 있고 입문자를 위한 다양한 자료가 있습니다. 모바일에 특화된 기능이 여럿 존재합니다. 또한 오픈소스 입니다.
두번째로는 Pin 입니다. Windows, Linux, macOS 를 지원하며 공식적으로 x86 아키텍쳐만 지원합니다. C/C++ 을 이용하여 코드를 작성해야 하며, x86 플랫폼에서 비교적 고수준 API들을 다양하게 지원하기 때문에 일반적인 시나리오의 x86 프로그램 분석에는 안성맞춤입니다.
세번째로 DynamoRIO 입니다. Windows, Linux, Android 를 지원하며 x86, arm 아키텍쳐를 지원합니다. Pin 에 비해 비교적 저수준의 API를 제공하며 따라서 더 어렵지만 복잡한 도구를 만들 수 있습니다. DynamoRIO 를 기반으로 한 다양한 툴들이 존재하기 때문에 해당 툴의 코드를 보고 입문할 수 있습니다. C/C++ 로 코드를 작성해야 합니다. 또한 오픈소스 입니다.
네번째로 QDBI 입니다. 비교적 가장 최신에 개발되었고 Windows, Linux, MacOS, Android 와 x86, arm 아키텍쳐를 지원합니다. C/C++, Python으로 개발이 가능하며 Frida 바인딩을 제공하기 때문에 쉽게 입문할 수 있습니다. 최신에 개발되었다 보니 자료는 많이 없지만, 개발진들이 올려놓은 블로그 포스팅을 참고할 수 도 있어 처음 입문하기에도 좋은 것 같습니다. 또한 오픈소스 입니다.
참고자료
Luk, C. K., Cohn, R., Muth, R., Patil, H., Klauser, A., Lowney, G., Wallace, S., & Reddi, V. J. (n.d.). Pin: Building customized program analysis tools with dynamic instrumentation. Intel Corporation and University of Colorado.
Bruening, D. L. (2004). Efficient, transparent, and comprehensive runtime code manipulation [Doctoral dissertation, Massachusetts Institute of Technology]. MIT Department of Electrical Engineering and Computer Science.